{kind=link}
Except for goma, all of these publicly available distributed compilers share the issue that they do not take measures to reduce the amount of needed upload bandwidth. When the COVID-19 pandemic started and working from home became a usual practice, this limitation was crucial: when working from home, engineers only have some MBit/s of upload bandwidth available in contrast to the Gigabit Ethernet link in the office. This poses a bottleneck for distributed compilation and makes working from home less efficient. The other distributed compiler being able to cache dependencies is goma: a quite large and complex project, which is not open-sourced in its entirety (there is another version of goma that is kept internal) and hard to tailor to a specific need due to its complexity.
This is why we developed our own distributed compiler, called homcc (pronounced həʊm siː siː), from scratch. In contrast to other available distributed compilers, homcc explicitly caches dependencies (such as header or source files) on the server so that they do not have to be sent from the client to the server repeatedly therefore, once the cache is warmed up, almost no upload bandwidth is required.
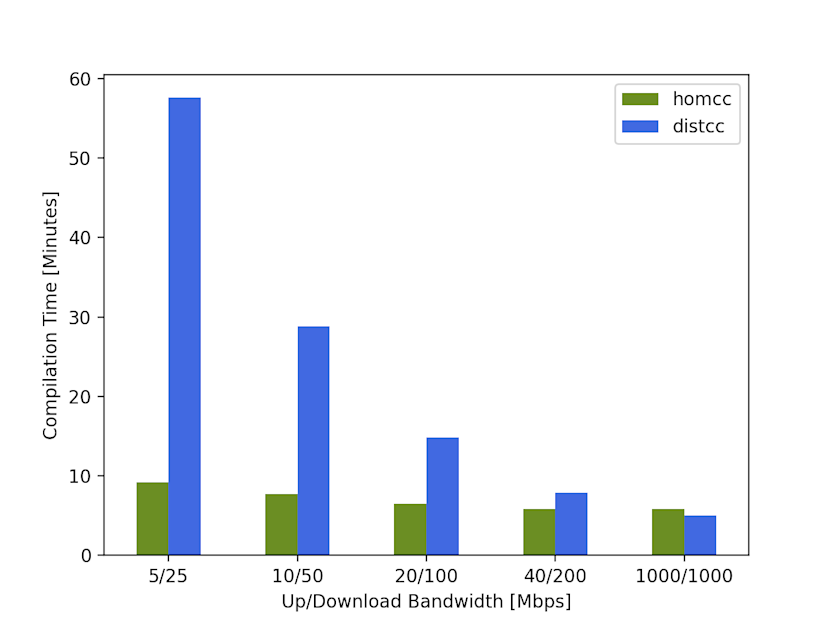
Comparing homcc with distcc shows that this leads to significantly reduced compilation times in environments where there is less than a Gigabit Ethernet connection available:
{kind=link}
The benchmarks were performed on a code base resulting in over 1000 compilation units. For building, clang++-14, CMake and Ninja were utilized with 60 concurrent compilation jobs. wondershaper was used to limit the bandwidth during the benchmarks, simulating a working-from-home scenario. One can see that distcc fails to offload the compilation jobs in a timely manner for an available upload bandwidth under 10 Mbps. It is effectively slower than a local build in these scenarios, which takes about 25 minutes on our developer machines. On the other hand, the homcc compilation times stay relatively constant independent of the available bandwidth.
To further reduce the bandwidth needed to offload compilations, homcc currently offers two compression algorithms (LZMA, LZO). But how does the offloading of C++ compilations even work and how does homcc minimize the traffic so much in detail?